
You've been using Redux for a while now. It was exciting at first, but the amount of code you need to ship a new feature is starting to creep upwards.
The line between your application state and data cache is blurred and you wonder how your redux store managed to become so complex despite countless efforts to keep things simple.
With every new addition to the backend, you find yourself making sweeping changes across the project. Actions, reducers, containers — it feels like you're touching every file in the codebase and you ask yourself: Were things always this complicated?
Does this sound familiar?
First things first — you're not alone. Redux is the industry standard for managing application state, and while some of the problems mentioned above can be attributed to Redux, much of the complexity originates from the way we currently manage front-end caching with REST backends.
To understand this problem, let's look at the typical approach for front-end caching with REST and compare it to GraphQL.
Actionable changes with REST
If you've ever used the classic Redux + REST combo, chances are you're familiar with this approach. It goes a little something like this:
- Fetch data from REST API.
- Parse data and add to a local store.
- As a pushing action occurs (POST, PUT, DELETE, etc.) update the local state to reflect the changes in your app.
At first this seems like a reasonable way to do things. As a new item is pushed to the backend, we add that item to our local store. When a push to the backend occurs and an item is changed, we change it in our local store.
Unfortunately, our REST backends are often more than just an API for working with normalised data. There will be numerous API calls where changes to a single item cascade across our whole data model, and suddenly our simple caching implementation becomes a complex layer of redundancy that needs to be actively maintained.
Introspection assisted caching with GraphQL
Most GraphQL clients in React (such as URQL or Apollo Client) don't require any reducers to mirror changes to the backend. Instead, any push to the backend will immediately update the values in the local cache, but how does this work?
Introspection is one of the single most impressive parts of GraphQL. While a REST client would need bespoke logic to parse data into the local cache, a GraphQL client is able to get additional information about the type of data being returned—and therefore, that data can be stored in a normalised format.
// Example mutation addComment($postId: Int!, $text: String!) { Id comments { Id text __typename } __typename } // Example response { Id: 1, comments [ { id: 5, text: "I'm normalised!", __typename: "comment" } ], __typename: "post" }
In the above example you can see a request and response for "adding a comment to a post" in GraphQL. Unlike REST, because we are able to make use of introspection, the single object in our response can be identified as being two different data types to parse into our cache—a post with an id value of 1, and a comment with id of 5.
The major difference here is that the caching logic is no longer tied to the data model, meaning that it can be abstracted and reused across multiple projects. We're now consistently getting the changes to our data directly from a single source (our GraphQL API) rather than from making manual local mutations based on API responses.
That was a lot to take in...
You're right, let's break this down.
Actionable caching with REST
✅ Caching of backend data
❌ Redundant layer of backend logic
❌ Complex modeling of data relationships
❌ Project specific caching logic
❌ Multiple sources of truth
Introspective caching with GraphQL
✅ Caching of backend data
✅ Normalised storage of data
✅ Decoupled & abstracted caching logic
✅ Single source of truth
Fine, I'll move to GraphQL
If only it were that easy. I recently asked the people of Twitter what backend they're working with, and it's clear that many are still using REST.
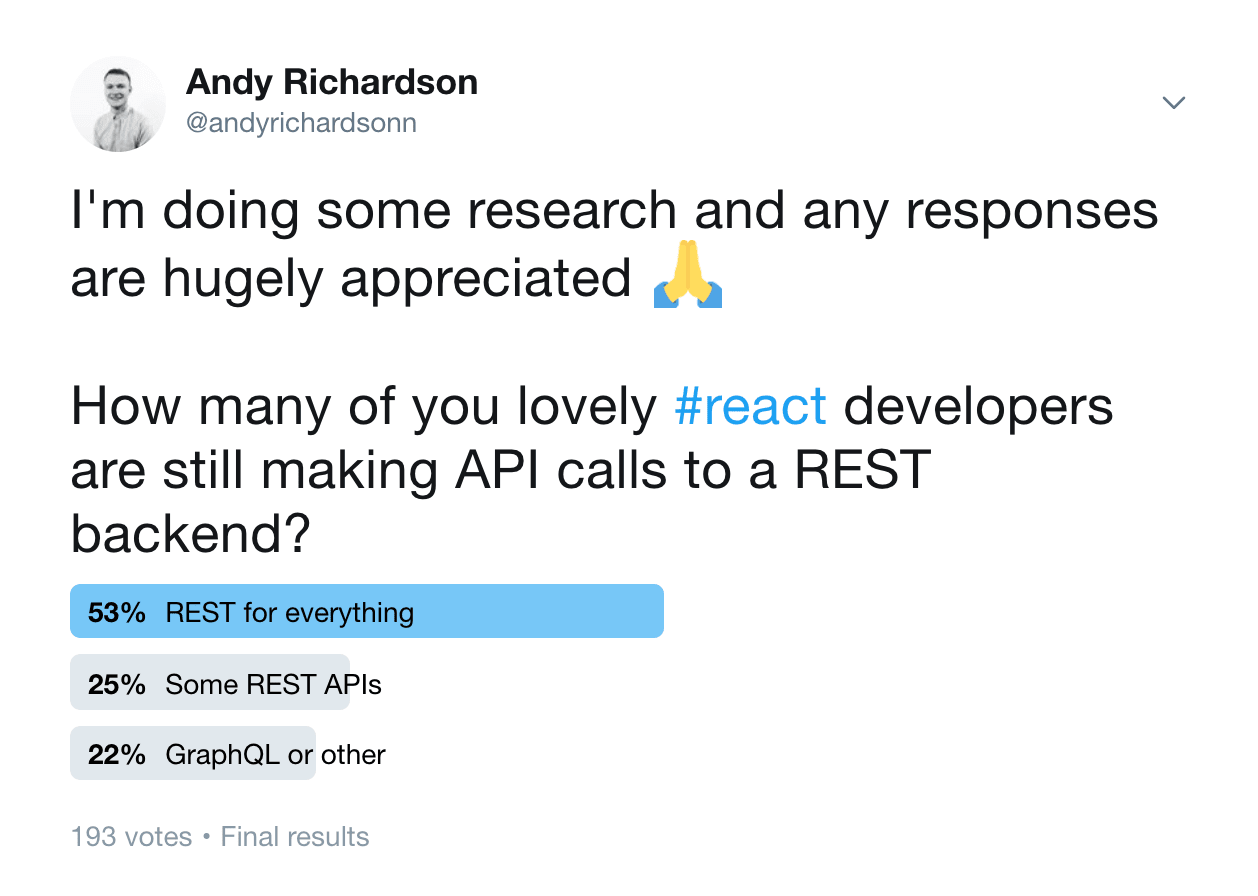
While GraphQL has some compelling advantages, it's clear that REST is still putting up a fight. We need a simpler solution on the client side.
Introducing Tipple
It was this exact problem I encountered a few weeks ago that spawned the idea for Tipple. A client-side library that handles caching for the REST backends of yesterday, but in a manner that is inspired by the GraphQL clients of today.
While a schema-agnostic normalised caching implementation with REST doesn't look to be possible, there are things we can do to implement caching which address the following:
- reduces redundancy
- abstracts caching logic
- uses a single source of truth
How Tipple works
At the very core, Tipple uses routes to cache data. While not as runtime efficient as managing your own normalised implementation, it's a huge reduction of complexity and ensures that your data is only being sourced from a single source of truth—your REST endpoint.
A request in Tipple looks a little something like this:
const [state, refetch] = useFetch('/todo', { domains: ['todos'] });
For the most part, this looks like a typical fetch API call, however, because this API is implemented as a hook, the fetching state is managed for us. The second difference is the domains property in the second argument.
Domains in Tipple are similar to the __typename property in GraphQL that was discussed earlier. In REST, we might consider a domain to be a resource type, but for all intents and purposes, it's a way of uniquely identifying a subset of our data model. By specifying the domain when we make a fetch, we're explicitly stating the data domain for which our fetch is dependent.
Here is a hook for pushing changes. See if you can guess what happens to the previous useFetch example call when this is executed.
const [state, execute] = usePush('/todo', { domains: ['todos'], body: JSON.stringify(todo) });
You can probably see where this is going. Now when we trigger a push to our backend (in this case, adding a new todo item) we specify the domains which will be invalidated. This in turn causes any mounted useFetch hooks to be refetched if they are dependent on the 'todos' domain (such as the prior example useFetch call).
So, this is the perfect solution?
Not entirely—every approach has its pros and cons, and Tipple is no exception.
The upside is, you will have much less code in your project—if complexity is your jam and you like seeing that line count grow, you'll be disappointed by how this simplifies your project.
The downside is that Tipple will likely increase the frequency of refetching data from your endpoints. Changes to a domain cause all mounted useFetch calls dependent on that domain to be refetched, so while there's no need to implement an action, reducer, and container for your 'add todo' API call, you will be refetching that list of todos every time a push is executed.
Fortunately, hooks in Tipple are coupled to the React component lifecycle. This means that refetches will only be occurring if your component is mounted. You'll only refetch the data you need on the screen. Otherwise, that refetch can be made next time the dependent component is mounted.
Tipple is an Experimental project. We're looking at ways in which this approach can be optimised, so do star the repo to keep up to date. If you have any thoughts, suggestions, or feedback, get in touch and let's make REST more enjoyable to work with!


