

Prisma is a next-generation object–relational mapper (ORM) that claims to help developers build faster and make fewer errors. Prisma takes a different approach to ORMs compared to traditional ORMs. It uses a custom Schema Definition Language (SDL) that automatically writes migrations and generates type-safe code. Unlike TypeORM and MikroORM, Prisma does not use classes or decorators for model definition. It instead uses code generation from schema, similar to the popular GraphQL Code Generator utility. This generated TypeScript code is used by the Prisma Client for stricter type safety and rich IDE auto-completion features. Later in the post, we will compare Prisma to TypeORM and how Prisma solves some issues that could still lead to runtime errors in TypeORM.
Comparing the approach with Prisma 1, which required a custom server running in a container to transform calls to database queries, which pushed away a lot of early adopters, Prisma 2 completely changes the approach, using a pre-compiled binary instead.
How Does Prisma Work?
Prisma takes the models written in the schema and with the prisma migrate command generates the SQL migrations as well as types that are stored in node_modules/.prisma/client. These types are aware of the relations that are created in the models as well as provide generated code that can be used to query the models. In the section below, we will take a closer look at how to create models and use them with the Prisma client. When you query using the client, it takes the queries and passes them to a Query Engine binary that optimizes it and converts it to a database query.
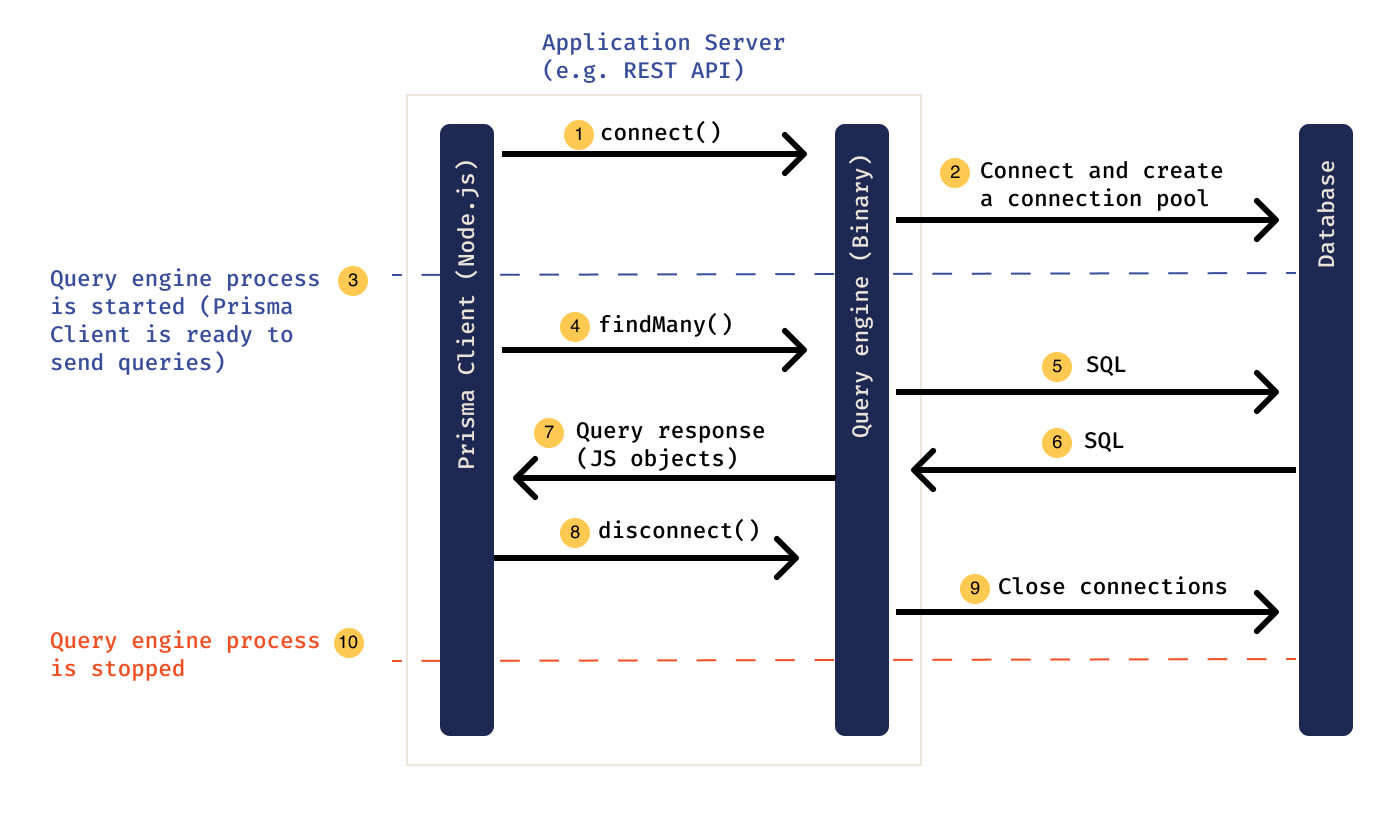
Describes the Prisma architecture. Source: Prisma Docs
Prisma's engine is something you would not have to interact with ever when working with Prisma, but it helps us understand how Prisma works. All communication to the database layer happens via the engine. The optimization the engine provides does have benefits—one of the biggest being that it solves the N+1 relationship problem, which is common in GraphQL applications.
Creating Our First Model
Let's start exploring Prisma by creating a simple library application where we have books with multiple authors. First we will bootstrap a Prisma application using this script:
curl -L https://pris.ly/quickstart | tar -xz --strip=2 quickstart-master/typescript/starter
This will create a new folder starter that we will navigate to using cd starter and run npm install.
The starter comes with some boilerplate for us to get started. We will look at the prisma folder and all the files that have been automatically created. The .env file can be used for specifying environment variables such as database URL, username, and password from which the Prisma SDL can read. dev.db is for SQLite, which we will be using for this tutorial.
The most important file is the schema.prisma, which is the SDL we will use to define our models. Let's delete everything in the file and replace its contents with the following, as we will write our own models and not use the one provided in the starter:
datasource db { provider = "sqlite" url = env("DATABASE_URL") } generator client { provider = "prisma-client-js" }
In these lines, we are defining our data source and letting Prisma know that we will be using SQLite. The URL for it will come via the environment variables. Finally, the generator is used to let Prisma know which language we will be using with the Prisma client. In this case, it will be JavaScript.
We will now create our first model which will define our book entity:
model Book { id Int @id @default(autoincrement()) title String description String? }
Let's break this model down and understand what everything means.
Model
model correlates to a table name in the database. The name of the model should adhere to the following naming conventions:
- Must start with an alphanumeric letter and otherwise consist of more numbers, letters, or underscores
- Must start with a letter and is typically spelled in PascalCase
- Should use the singular form (for example,
Userinstead ofuser,usersorUsers)
Fields
Fields are defined in the following syntax:
name of the field type of the field any attributes
In the case of id, we want the id to be of type Int and this will be the primary key that is defined using @id attribute. Finally, we want to automatically increment the id by default for it to be unique. This is achieved by using @default(autoincrement())
Check out these links for a list of all the Types and Attributes supported by Prisma
- https://www.prisma.io/docs/reference/api-reference/prisma-schema-reference/#model-field-scalar-types
- https://www.prisma.io/docs/reference/api-reference/prisma-schema-reference/#attributes
? after the type indicates that the field is optional.
Migrations and Prisma Client
Just by writing the model, Prisma does not automatically update your database. We will need to create a migration and run it against our database. In development, this can be done using the following command:
npx prisma migrate dev --name init
This will create a new folder, migrations, in the prisma folder. Prisma will automatically create a SQL file which, in development, is automatically run against the database. Prisma also generates the types declarations for all the models that can be used with the Prisma Client for TypeScript.
Jumping to the script.ts file located at the root of the project, we can see that there is some boilerplate already setup for us to start using our Prisma client.
To connect to our database using Prisma client, we need to import and instantiate it:
import { PrismaClient } from "@prisma/client"; const prisma = new PrismaClient();
All the methods to query our data are located on the prisma variable itself. Let's create a new book and query all the books in our database.
Inside the main() function we will paste the following code to create a new book:
const book = await prisma.book.create({ data: { title: "Effective JavaScript", description: "Effective JavaScript is an in-depth look at the JavaScript programming language and how to use it effectively to write more portable, robust, and maintainable applications and libraries. Using the concise, scenario-driven style of the Effective Software Development Series, this book brings together tips, techniques, and realistic code examples to explain the important concepts in JavaScript.", }, }); console.log(book);
We can run the script by running npm run dev. After the script successfully runs, we should see the new book printed to the console.
Let's make sure that we can see this book when we query for all the books, which we can do using the following code:
const allBooks = await prisma.book.findMany(); console.log(allBooks);
Running the script again with npm run dev, we return with an array with our book Effective Javascript as the only entry.
This link provides a list of all the available methods available on models that can be used to query or update the data.
https://www.prisma.io/docs/reference/api-reference/prisma-client-reference#model-queries
Adding a Relationship
Let's look at how we can add a relation to our book model by adding a many-to-many relationship with author. Open schema.prisma again and update the book model with the following lines and add the author model
model Book { id Int @id @default(autoincrement()) title String description String? authors Author[] } model Author { id Int @id @default(autoincrement()) name String books Book[] }
Running npx prisma migrate dev --name author will generate another migration for us. Let's take a look at what SQL code Prisma generated for us:
-- CreateTable CREATE TABLE "Author" ( "id" INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT, "name" TEXT NOT NULL ); -- CreateTable CREATE TABLE "_AuthorToBook" ( "A" INTEGER NOT NULL, "B" INTEGER NOT NULL, FOREIGN KEY ("A") REFERENCES "Author" ("id") ON DELETE CASCADE ON UPDATE CASCADE, FOREIGN KEY ("B") REFERENCES "Book" ("id") ON DELETE CASCADE ON UPDATE CASCADE ); -- CreateIndex CREATE UNIQUE INDEX "_AuthorToBook_AB_unique" ON "_AuthorToBook"("A", "B"); -- CreateIndex CREATE INDEX "_AuthorToBook_B_index" ON "_AuthorToBook"("B");
When we specify authors Author[] and books Book[] Prisma understands this is a many-to-many relationship and automatically creates a join table for us, which we don't have to worry about when interacting with the data.
Now let's take a look at how we can interact with this data using the client. First, let's clear all the data currently in our DB and start fresh. We can do so using the following code:
await prisma.book.deleteMany()
We will now create a book and author in the same call. Let's take a look how we can do that:
const newBook = await prisma.book.create({ data: { title: "Effective JavaScript", description: "Effective JavaScript is an in-depth look at the JavaScript programming language and how to use it effectively to write more portable, robust, and maintainable applications and libraries. Using the concise, scenario-driven style of the Effective Software Development Series, this book brings together tips, techniques, and realistic code examples to explain the important concepts in JavaScript.", authors: { create: { name: "David Herman", }, }, }, }); console.log(newBook);
When we run the script again with npm run dev, we will see only the book information logged to the console but not the author. We will look at why that is the case later. Before that, let's understand what is happening in this method.
We are creating a new book, but we are also creating a new author using the create key, which tells Prisma to create the author and also to add an entry in the join table connecting the book and the author.
Now, if we try to query the books using await prisma.book.findMany() we will not see the author again in the console. This is because, by default, Prisma does not automatically join all the relations; we have to manually specify which relationships we want to include in the query. To do so, we use the include keyword in the query. Let's take a look at the example again:
const allBooks = await prisma.book.findMany({ include: { authors: true } }); console.log(allBooks);
Because we didn't tell the client to include the related author's data in the last query, it was missing the author's data. To include relationships in the query we can use the include keyword to specify which relationships we want to join. In the above query include: { authors: true } joins the authors to the books.
Type Safety
We looked at how we can create, query, and delete data from our database using Prisma client. Let's now explore the real power of Prisma, which is the type safety it provides.
If you are using Visual Studio Code as your IDE it is highly recommended that you install the Prisma extension as it helps provide formatting, syntax highlighting, linting and much more in the Prisma Schema. It can be found on the Visual Studio Marketplace: https://marketplace.visualstudio.com/items?itemName=Prisma.prisma
Let's take a look at few examples where Prisma helps us prevent runtime errors especially when working with relationships:
const book = await prisma.book.findUnique({ where: { id: 1 }}); console.log(book.authors);
When we query a book by id we see two errors.
First Object is possibly 'null'. This means that when we query a book by id it possibly does not exist. We can use optional chaining here to fix the error by changing it to console.log(book?.authors); . This still does not fix the error Property 'authors' does not exist on type 'Book'. The reason for this is that Prisma is aware that, although the relationship exists for Book and Author, we have actually not told the client to do the join. To fix this we can change our query and we see that there are no further errors:
const book = await prisma.book.findUnique({ where: { id: 1 }, include: { authors: true }, }); console.log(book?.authors);
Compared to this, relationships in TypeORM are not strongly typed. It just assumes that the relationships are included and will not provide an error message when querying nested fields. However, in reality this is not the case and this could lead to runtime errors. This is just one instance where Prisma helps us reduce errors. While it is highly recommended to use Prisma with TypeScript, you can use Prisma with plain JavaScript as well.
Conclusion
In this simple tutorial, we looked at just a few of the many things Prisma does well. In addition, the Prisma Studio, which is helpful for browsing your data, is part of the Prisma CLI and can be accessed with npx prisma studio
Prisma documentation is also a great resource for finding exact answers for doing something specific with Prisma. https://www.prisma.io/docs/


