

For the unfamiliar, Chaos Engineering is a relatively new (well, since 2011) field and discipline within software engineering where services are experimented on directly in production. The main attraction can be to simply “break the system and see what happens”—a far cry from the traditional “keep everything running at all costs.” The experiments’ goals are typically to understand a service or system’s tolerance levels against different types of failures.
When some think of Chaos Engineering, they may only see how common areas like resiliency, security, and performance can be improved in a system. However, one such experiment also taught me that Chaos Engineering can help improve your team’s incident response mean time to recovery (MTTR)!
Why Chaos Engineering?
With the use of cloud providers becoming the norm, the adoption of Chaos Engineering will continue to organically grow. As we depend more on our cloud providers, we also need assurances of availability when new and unexpected outages occur. This is where Chaos Engineering will help. Unit or integration testing typically verifies components or functions of application code and how it is supposed to respond. However, Chaos Engineering focuses more on how an application actually responds when faced with a wide range of failures. This can be anything from removing access to a network file share to deletion of database tables to observe how a service responds. The range of failures is endless.
What I find most interesting about Chaos Engineering is the freedom provided by having zero expectations about how an application is going to respond when injecting these particular failures. This is liberating as we often expect applications and services to return results in a particular fashion during unit or integration testing. Now, we can actually say “let’s try and break this application to see what happens” and let the creativity flow!
How Can Chaos Engineering Help in Practice?
The above sentiments are all well and good in theory, but how do Chaos Engineering experiments help in the real world? Well, I can demonstrate how a small Chaos Engineering experiment actually led to outcomes that were later utilized during a production incident.
Chaos Engineering Experiment Setup
The experiment was as follows: take a Kubernetes cluster in a non-production environment, inject failures to the running pods, and record how the service responds. That’s it. Nothing groundbreaking, but a move few teams would focus on when it comes to creating services. The particular service experimented on ran pods in a parent-child architecture, where the parent was an “orchestrator” that would spin up child pods when requested. The child pod logs were also streamed in real-time via a webpage outside of Kubernetes, where clients would view logs of their job requests.
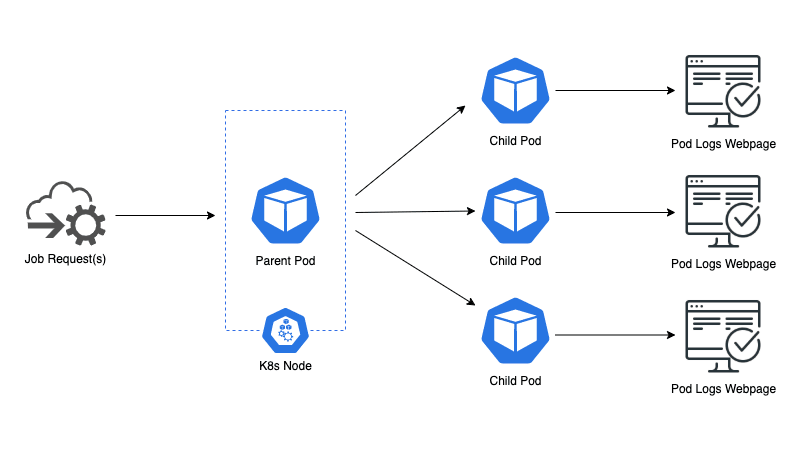
The architecture of Kubernetes’ environment and service
Running the Chaos Engineering Experiment
The experiment was designed to inject termination to child pods, the parent pod, and the underlying Kubernetes node during simulated scheduled tasks. The failures and errors returned during each of these tests were recorded, and the child pod logs webpage was observed to understand the client experience.
At the time of the experiment, the most interesting finding was the drift between the logs webpage and the Kubernetes pod logs on the cluster itself, along with some bug findings and expected failure modes in certain conditions. All experiment events and outcomes were recorded in a document and then discussed at a team meeting. As the experiment was performed safely in a non-production environment, with no outages occurring as a result, the document and resulting bug fixes received positive feedback and the experiment was declared a success. The service resilience was now further understood, as compared to before the experiment where the failure modes weren’t as well known.
Chaos Occurs in Production!
Some weeks later, however, a production issue arose where the parent pod was in an error state, with many child pods running that could not be deleted safely without potentially taking further downstream services offline. Looking for a solution mid-incident response to safely delete the parent pod without taking down the child pods, we reviewed our Chaos Engineering experiment document.
Upon review, we found there was a safe command to delete the parent pod without affecting the running child pods. All commands were recorded during the experiment to show how failures were injected and their outcomes. Interestingly, there was also a very unsafe command to delete the parent pod that would have had negative effects on the child pods and downstream services. You can guess which command was chosen during incident response 😉
Most satisfying was having the safe command and confidence in the outcome during the incident. The issue was swiftly dealt with, with no further outages, unplanned maintenance, or effect on clients who consumed the service. Reviewing the Chaos Engineering experiment document helped reduce our MTTR for this incident. This may seem like a “small win” but during an incident where one wrong command can make a bad situation even worse, you’ll be hard-pressed to find engineers that refuse the correct, and proven, command. Further, simply having the command also saved precious troubleshooting time during the incident.
Lessons Learned
What was most satisfying about the incident response was not the decreased MTTR—it was the reflection on what our Chaos Engineering experiment provided. The experiment was not designed to perform experiments to help streamline our incident response and reduce MTTR. The experiment was designed to inject failures and observe the response in order to gain a sense of the service’s resiliency, which was then documented. However, our outcome was a reduction in MTTR. Further, odd bugs and behaviors we observed were also turned into fixes and feature requests to help improve the service for the future.
Some engineers may think of non-production primarily as a place to test out feature changes to make sure these don't cause errors, to trial out memory or CPU increases/decreases to see if those improve performance, or to apply patches before they hit production to observe any issues. However, with Chaos Engineering, we can now think of non-production as a place to safely inject errors and then take those learnings to our higher-level production environments. Further, capturing those experiment results can be huge and act as a point of reference during an unintended incident!
When creating service offerings or setting up new technologies like Kubernetes, we tend to think about simply getting the service to “work.” That is no small feat and is often an underrated milestone. But when we use our imaginations and try to “break the service” in creative or esoteric ways, very interesting results can be captured. Those results and learnings can then be applied to your moneymaker— production—and can be very helpful when it matters in mid-incident.
I hope this article provides you with enough reason to set up a Chaos Engineering experiment on your systems and enjoy the outcomes as much as I did.
Paul will speak on this topic at Conf42: Chaos Engineering 2022 on March 10, 2022. For a full list of speakers please visit: https://www.conf42.com/ce2022
